Pour quelle raison l’estimation d’un Backlog augmente-t-elle ?
J’identifie deux origines possibles permettant d’expliquer pourquoi une estimation d’un backlog peut évoluer, et donc augmenter :
- Le travail à faire a réellement augmenté
- L’estimation du travail a été ajustée (au sens rendue « plus juste »)
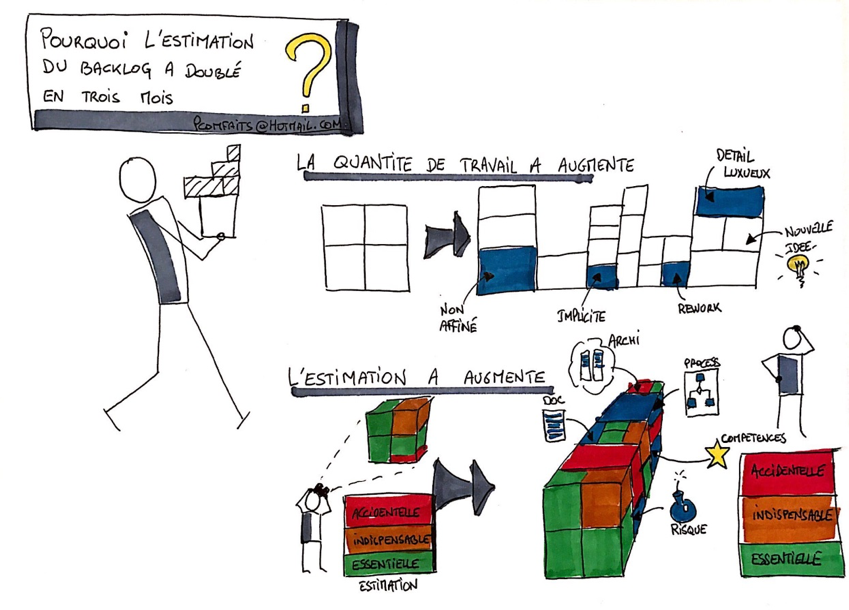
Figure 1 : origine de l’augmentation de l’estimation du BACKLOG
Le travail à faire a réellement augmenté
La première hypothèse est que la liste des fonctionnalités à réaliser a augmenté.
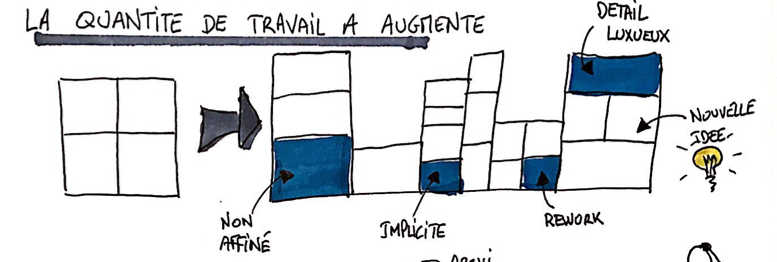
Figure 2 : Origine d’une augmentation du travail à faire
Les changements les plus évidents de cette catégorie sont les ajouts / suppression de fonctionnalités. Et ils sont simples à expliquer et à comprendre, voire à faire arbitrer.
- Des nouvelles idées, de nouvelles fonctionnalités
Malheureusement, les évolutions de backlog en Agile sont souvent plus subtiles. J’ai pu observer par exemple des augmentations liées à :
- Une complexification des fonctionnalités, des détails luxueux : par exemple en ajoutant un workflow, de nombreuses règles de gestion, des formats d’affichages, des aides à la saisie, etc.
- Des fonctionnalités « implicites » : qui ont été identifiées et ajoutées au backlog depuis le démarrage, mais qui implicitement faisaient déjà partie du périmètre
- Des fonctionnalités de grosses tailles qui n’ont pas encore été affinées, et qui selon la loi de Pareto, contiennent probablement 20-30% de détails nécessaires mais qui sont considérées globalement comme « indispensables »
L’estimation a augmenté
La seconde origine possible est un ajustement de l’estimation. Dans ce cas de figure, même si la quantité de fonctionnalité à traiter n’a pas changé, l’estimation a quant à elle bien augmenté.
Je recommande la lecture de l’article suivant sur le blog d’Olivier My pour mieux comprendre à quoi sert l’estimation, et pourquoi un mouvement est apparu ces dernières années : #NoEstimates. http://oyomy.fr/2018/10/estimation-et-agilite-un-paradoxe/
Pour expliquer ce phénomène je m’appuierai sur la définition d’une estimation selon trois catégories :
- L’estimation essentielle : l’effort à produire une fonctionnalité
- L’estimation indispensable : l’effort indispensable pour permettre à la fonctionnalité de fonctionner (exemple : avoir une Gateway d’API si on veut créer une API)
- L’estimation accidentelle : l’effort nécessaire pour réaliser le travail dans le contexte (exemple : processus de validation, gestion des contributions, réunions, compétences nécessaires…)
Si l’estimation essentielle a peu de raison d’évoluer, les deux autres catégories vont avoir naturellement tendance à augmenter, surtout au cours des premiers sprints, car l’équipe va découvrir son environnement.
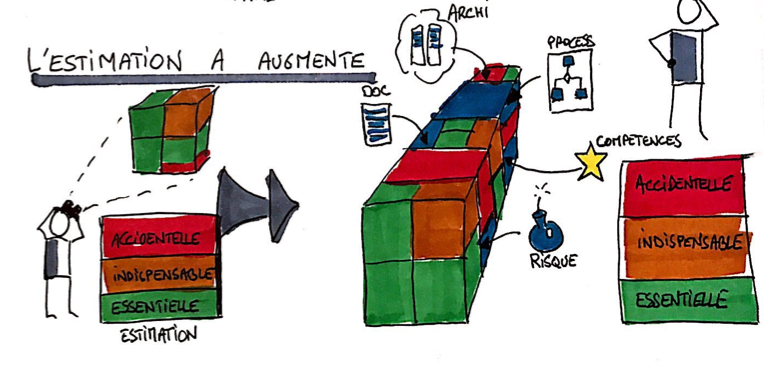
Figure 3: Origine d’une augmentation de l’estimation
En synthèse, le fait d’avoir réalisé quelques sprints de fabrication a permis à l’équipe de prendre en compte de nouveaux éléments de complexité accidentelle et indispensable :
- Contraintes de l’architecture
- Contraintes de l’organisation
- Risques
- Montée en compétences technique ou fonctionnelle
- Contraintes de process
- Contraintes de documentation
- Pression sur l’équipe
- La manière d’estimer a changé (personnes différentes, …)
- …